
Start in seconds
No download, no terminal, just out-of-box agentic thinking partner + canvas
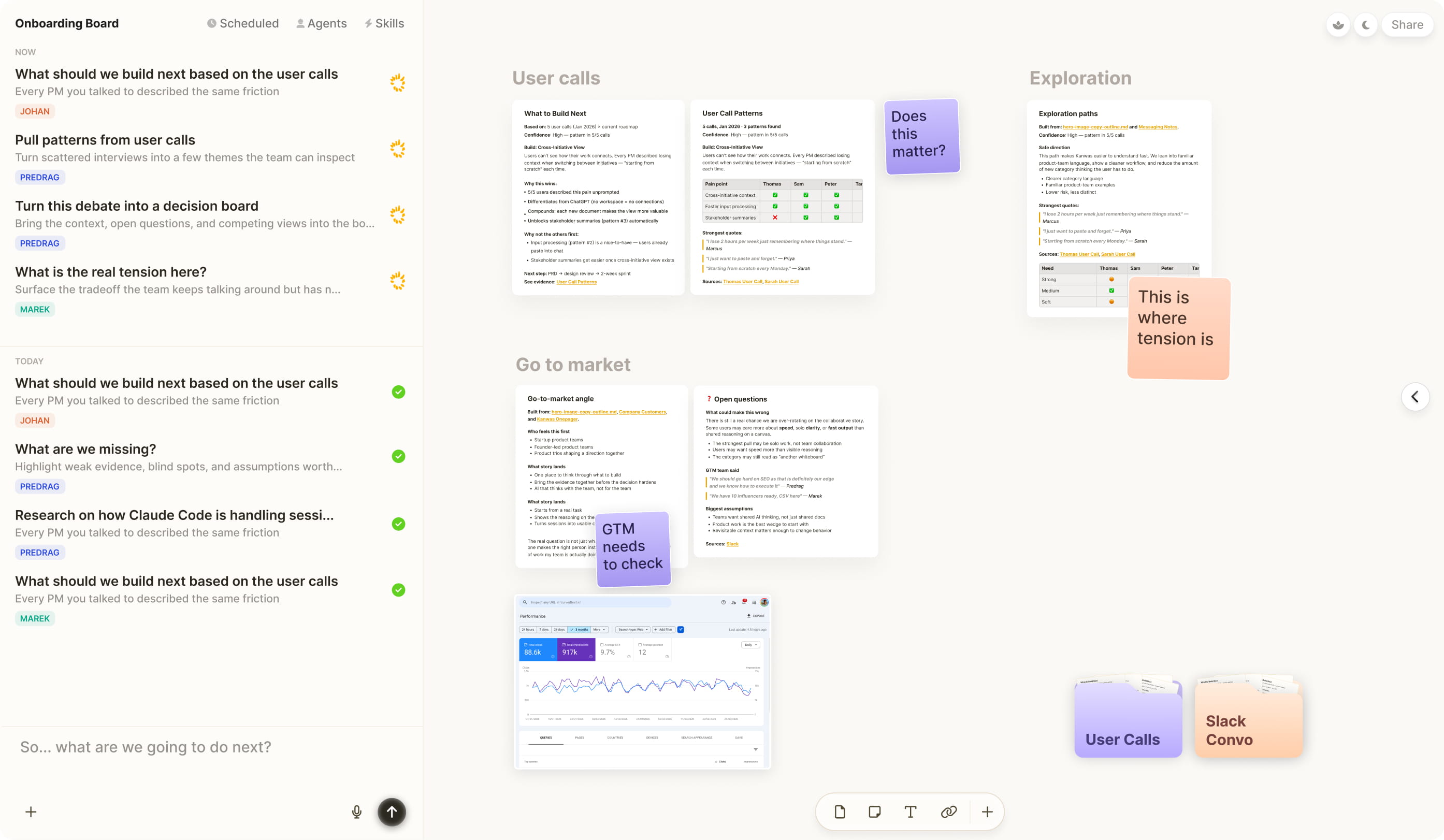
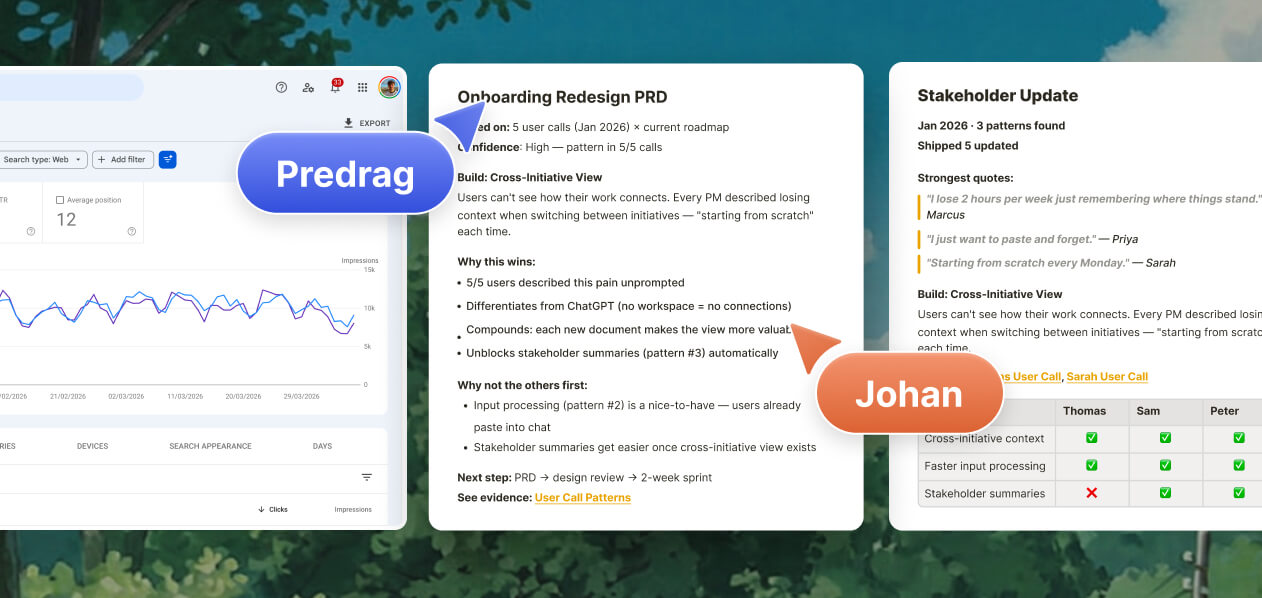
Kanwas gives teams & agents one place to create, edit, share and compound product context. Stop juggling Claude chats, local folders, Obsidian, VS Code, Git, and docs.


and more...




- Samuel Beek, Founder, Schematik


By learning about you, your business and your decisions. Building a transparent shared context.

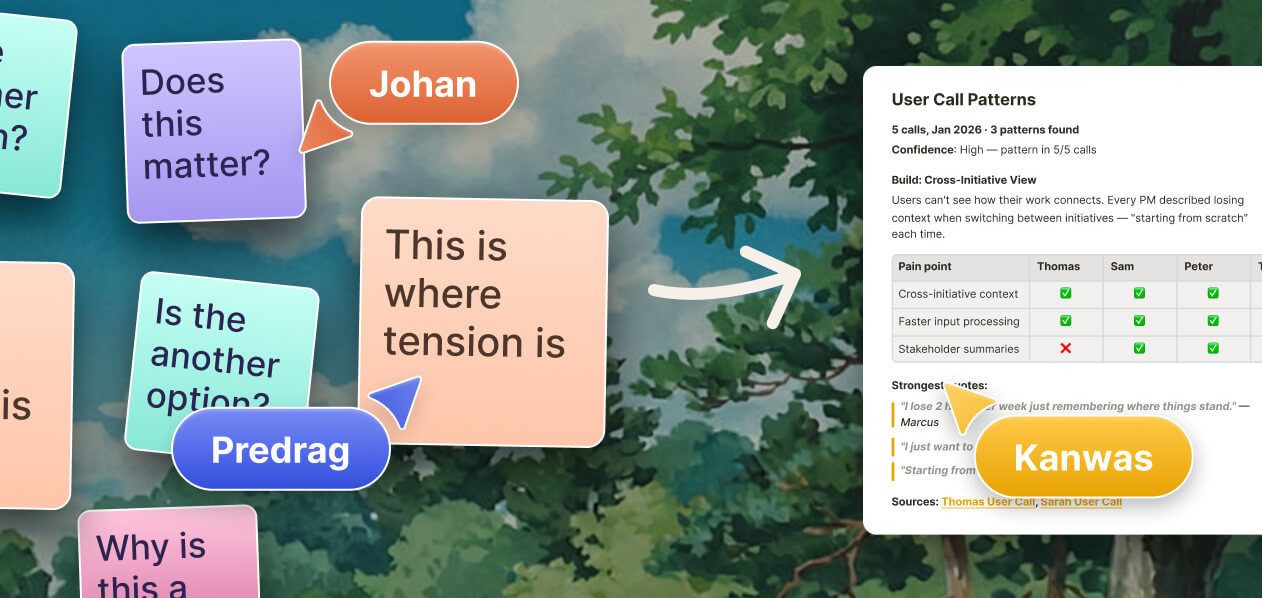
Work with your team and agents over the same context. Evidence, ideas and trade-offs, transparent to everyone.
Generate structured, execution-ready deliverables for every stage of implementation.
Every decision and outcome makes the next thinking and deliverable better than the last.






You've used ChatGPT or Claude to draft a strategy document and it hit every section. Fluent, confident, completely generic. It missed the point. The structure was there. The thinking wasn't. Not wrong, just not what you would have done. You iterate. It follows every piece of feedback, satisfies every criterion, but the thing you actually mean keeps slipping away like a bar of soap.
Same week, someone used Claude Code to build an app in a weekend what used to take a team a quarter. That worked. Really worked.
Why does AI crush code and fumble strategy? Why does it nail the structure of a strategic document but miss the soul of it? There's a pattern here, and it's not the one most people think.
Some work has a right answer. Code compiles or it doesn't. Call this convergent.
Other work has no right answer, only judgment. Is this the right strategy? Two smart people will disagree, not because one is wrong, but because it depends on what they bring to it. Call this divergent.
LLMs crush convergent work. They fumble divergent work. Everyone's noticed this. Most people stop here, "AI is good at some things, bad at others." But why it fumbles divergent work is the interesting part. And the answer turns out to be fundamental, not temporary.
Taste is the foundation for everything we value in knowledge work
We actually know what's behind divergent judgment. It's not mysterious. Neuroscience has this figured out.
Everyone's experienced it. You're in the shower, your mind wanders, and suddenly a genuinely good idea appears. You didn't produce it. You didn't reason your way to it. A hint of it surfaced from somewhere below conscious thought. Then your conscious mind picks it up, develops it, reasons about it: is it right? Does it hold up? But the seed came from somewhere else. That "somewhere else" is the mechanism.
The brain runs two systems. System 2, the conscious mind, is slow, deliberate reasoning: step by step, articulable, teachable. System 1, the unconscious mind, is fast pattern recognition built through experience. Millions of micro-exposures compressed into instant evaluation. When a great PM reads a spec and feels something is off before she can articulate why, that's the unconscious. Neural circuits firing before deliberate reasoning kicks in. Pattern recognition trained on years of shipping product. The unconscious is what we call taste, the judgment that experienced PMs bring to ambiguous decisions. It's compressed experience. Nothing more, nothing less.
And taste is the foundation for everything we value in knowledge work. Thinking is not just reasoning, it's intuition plus reasoning, unconscious plus conscious. The intuition generates candidates, spots patterns, flags what matters. The reasoning evaluates, sequences, articulates. You need both. Reasoning without intuition is a powerful engine with no steering. Creativity is the same: novel combinations that are also good. "Novel" requires specific context that lets you see connections others can't. "Good" requires taste to evaluate whether the combination is worth anything. Without taste, you get generation, not creation.
Now, LLMs aren't "just pattern matching." Through pattern matching at scale, they developed genuine reasoning ability. They reason. They solve novel problems. They chain logic in ways that surprise their creators. This is real and underappreciated. But reasoning is only one half of thinking.
The other half, taste, is where the models break down, and the reason is structural.
A PM's taste is the output of one particular brain processing decades of unique experience. Every decision watched, every launch shipped, every market shift lived through, compressed into neural circuits that fire in milliseconds. There's a principle from computational complexity that matters here: computational irreducibility. For complex systems, you can't predict the outcome without running a simulation at least as complex as the system itself. There is no shortcut. The brain processing decades of specific experience is exactly such a system. To replicate a PM's taste, you'd need to simulate that specific brain with those specific decades of context. There is no compression that preserves it.
LLM training does the opposite. It compresses everyone's experience into a single distribution. The result: superhuman reasoning, average taste. Not zero, just average. The compression doesn't eliminate taste, it averages it across everyone. And average taste is the same as no taste. It's generic. The median of everyone's judgment is nobody's judgment. Training on the outputs of a thousand PMs doesn't simulate any one of them, it averages them. It's why every AI-generated strategy sounds plausible and none of it sounds like yours.
And the specific context that makes taste useful (what the right call is for your product, your market, this moment) was never in the training data to begin with. It's in your head. No corpus contains it. No amount of scale produces it.
So the models can't think well (superhuman reasoning, average intuition, mediocre thinking). They can't have taste (averaged away). They can't be creative (average taste, no specific context, average combinations). Not because the architecture is wrong. Because the process that produced taste is computationally irreducible, and training tries to shortcut it by averaging, which destroys exactly the specificity that makes taste useful.
There is no training fix for this. Not a bigger model. Not more data. Not better RLHF. This is a wall, not a gap.
And yet, context is the most undervalued concept in AI right now. People see generic outputs and conclude the models can't reason. The models reason fine. They have nothing specific to reason about.
This is where you need to do the work. The model needs your context (your product's history, your market's nuances, your team's constraints), and only you can provide it. This is also where most people give up. They get generic outputs, blame the model, and walk away. Which means this is exactly where you pull ahead. The people willing to do the context work get disproportionate returns from AI. Most won't bother. That's your edge.
Which raises the question: is there any evidence this theory is right?
Yes. The labs proved it, accidentally.
They built synthetic taste for code. Using RL (reinforcement learning), a training setup where the model tries something, gets feedback on whether it worked, and adjusts, they ran millions of agent loops with fast, real feedback: tests pass, code compiles, benchmarks improve. The model has "lived" millions of debugging sessions. It recognizes architectural dead ends before reasoning through them. That's taste. The unconscious built through synthetic experience, the same way the brain builds it through real experience.
This is why coding AI feels different in kind. The models haven't just gotten better at reasoning about code. They've started to know code the way a senior engineer knows code.
Three things made this possible. Code has fast, automated feedback: you can run a million loops and know which ones worked. Correct code is correct code, specificity matters less. A function that sorts a list is right or wrong regardless of your company's context. And code just needs to work.
Product work has none of these properties. Feedback is slow, you ship and wait months to learn whether the call was right. Correctness is subjective, two smart PMs will make different calls, and both might be right for their context. The value is entirely in the specificity: the right strategy for this company is wrong for that one. Product strategy needs to convince, to frame, to reflect judgment about what matters. The aesthetic dimension (how you frame the tradeoff, which nuance you foreground) is itself the work. You can't RL your way to that. Even if the labs invest in PM-specific training, the compression problem remains. You can train on a million product decisions, but the average of a million product decisions is a generic product decision. The specificity that makes taste useful gets destroyed in the same compression that creates the model.
And here's the counterintuitive part: the better the reasoning gets, the more visible the taste gap becomes. Ask the next frontier model to write a product strategy for your specific market, and it'll sound more polished, more structured, more confident than the last one. And it'll still miss every nuance that actually matters. The competitive dynamic your team just navigated, the trust issue with that enterprise account, the technical debt that makes the obvious roadmap impossible. More reasoning power without your context just means the model goes off-course faster and more convincingly.
Look at what the industry calls paradigm shifts. ChatGPT was RL fine-tuning over a base LLM. Test-time compute (o1, o3) is RL training models to reason longer before answering. Agentic loops are RL over tool-calling sequences. Three "revolutions," one idea: reinforcement learning over LLMs, taken further each time. And every iteration improves the same thing: the conscious mind. Better reasoning, longer chains, more tools. The unconscious improves only slightly (base model scaling has basically plateaued, and RL doesn't touch it). This is the trajectory, and it's why Ilya Sutskever argues that scaling compute alone isn't enough to advance AI. There is no signal that a new architecture solves this. Our research suggests it may not be possible in principle. And every major lab is all-in on scaling LLMs, the paradigm that strengthens the conscious mind and leaves the unconscious behind.
For product work, the taste problem has no solution on the training side. The labs can't build it. Scale can't produce it. The wall is real.
So if taste is the bottleneck, and context is what taste is made of, which roles need it most?
PM work splits cleanly along the convergent/divergent line.
The convergent part: writing status updates, formatting specs, pulling metrics, synthesizing meeting notes, keeping tickets organized, running competitive scans. This is real work. It eats hours. And AI agentic systems will take it over completely, not eventually, now. Scale alone gets you there. None of this requires taste. It requires diligence, and machines have infinite diligence.
The divergent part: deciding what to build, what to cut, which tradeoff to make, when to push back, whether this quarter's roadmap actually serves the strategy or just appeases stakeholders. This is where all the value lives. This is pure taste, pattern recognition trained on years of product experience. A PM without taste in this part is a project manager.
As AI eats the convergent half, what's left of the PM role is the divergent core. The taste. PM becomes more purely a taste role.
And the taste depends directly on context. Data is "churn went up 3%." Context is "churn went up because the pricing change broke the value prop for mid-market, which we know from the last three research rounds, and this is the segment sales is struggling with after the competitor move in Q2." The PM who holds that context makes better calls. Not because she's smarter. Because her taste has more to work with.
We also see PMs responding to AI eating the convergent work by going deeper into engineering and delivery, prototyping, building. In practice, the future probably demands both. Taste to decide what matters, and the hands-on ability to make it real without waiting for a full team to spin up.
The PM who can move between divergent thinking and direct delivery, who can read the market and ship the experiment, becomes disproportionately valuable.
And this context lives nowhere. Slack threads disappear. Docs become graveyards. When a PM leaves, the context walks out. When a new one joins, they spend months rebuilding what was never designed to be carried. Every PM tool stores artifacts. Storage gets worse with use. More documents, more noise. What PMs need is the opposite: something that gets better with use. Accumulation, not storage.
So the PM role requires exactly what LLMs can't do: taste built on specific context. The PM's context problem is exactly what current tools don't solve. And every time technology makes execution cheaper, the bottleneck moves up to taste. The question shifted from "can we build it?" to "should we build it?" Product thinking is the scarce resource. And it's getting scarcer.
What if you could give the LLM's superhuman reasoning the PM's specific context?
We just spent four sections arguing that the taste problem is unsolvable. Training compresses specificity. The specific context was never in the corpus. Computational irreducibility says you can't shortcut it.
All of that is true if you're trying to solve it through training.
But we never said the model can't operate with taste. We said training can't produce it. The reasoning is superhuman. The architecture works fine. The only thing missing is specific context. So what if you don't try to bake taste into the model? What if you accumulate context alongside it, not through training, but through use?
This isn't a complete solution. It doesn't give the model real taste. It doesn't make it creative. But when you feed superhuman reasoning specific, high-quality context instead of averaged context, the output starts to look remarkably like taste. Not perfect. Not human. But enough to cover the vast majority of PM work, including the divergent parts that matter most. The partial solution might cover 90% of the territory we just said was unreachable.
That's what Kanwas does.
One workspace where your product context lives, connects, and compounds. Not docs that rot. Not chat that disappears. A spatial environment where every decision logged, every PRD drafted, every meeting prepped builds on everything before it. Your product's history, your market's dynamics, your team's constraints (accumulating in one place), always accessible, always connected.
A PRD isn't purely convergent. The structure is straightforward; any model can fill a template. But the questions it asks, the tradeoffs it surfaces, the assumptions it challenges, that is taste. From day one, Kanwas brings curated product thinking to tasks that look routine but have a divergent core. The PM notices immediately: this isn't a ChatGPT PRD.
Underneath, AI agents read your workspace. They connect to Slack, Linear, Notion, your codebase. They draft, research, surface what changed. Everything you do makes them sharper; context accumulates as a byproduct of your work, not as homework.
And then the moment arrives. Superhuman reasoning meets your specific context. The feature being cut was the top request from the churning segment. The technical constraint from last quarter conflicts with the new spec. The competitive move from Q2 invalidates an assumption in the roadmap. The thing that kept slipping away like a bar of soap gets caught by the system. Not because it learned taste. Because your taste is already in the workspace, and the reasoning finally has something real to reason about.
Three things we believe:
We're dedicated to building the best place for product thinking work. Not AI wrappers. Not templates. A workspace where product thinking compounds. Our differentiator is focus: we only do this one thing, and we do it deeply.
We believe in collaboration between AI and humans. The thesis proves why: reasoning without taste is empty, taste without reasoning is slow. The best product work comes from humans and AI thinking together, each contributing what the other can't.
We believe AI should work while the human sleeps. The convergent half of PM work shouldn't wait for the PM. The AI handles it autonomously, informed by accumulated context. When you wake up, the work is done right.
And every model the labs ship makes this better. Every dollar spent on better reasoning is a free upgrade for Kanwas users. We're not building against AI progress, we're building the thing that makes AI progress actually useful for product work.
Delivery capacity is about to explode. Coding AI means every company will be able to build anything. The bottleneck for the entire software industry moves to the question above it: what to build. Product thinking becomes the scarce resource. A tool that can widen that bottleneck (on a fundamental level, not with wrappers and templates) is as big as vibe coding. Bigger, because it sits above it.
Did this thesis read well? 98% of this document was written by an LLM.
But look at the context it needed: cognitive science, neuroscience, computational complexity, machine learning theory, creativity research. A co-founder's three months of dogfooding his own product. A decade of product management experience. The lived frustration of watching the thing you mean slip away like a bar of soap across hundreds of iterations. The experience of the agent going from generic to "genuinely a better PM than me" once context accumulated.
And taste (the human kind): to feel when something was off, spot contradictions the model missed, and know when a sentence landed.
The model reasoned. The human tasted. The context made it work.
That's the core of the thesis. You just read the proof.
Full bibliography for the Kanwas Thesis.
Cognitive Science & Dual-Process Theory
Expertise & Pattern Recognition
Creativity & Cognition
Neuroscience
Computational Complexity
AI & Machine Learning
AI & Creativity
Industry
